Yes, most of the time. But describing things with boxes and lines is not always the best idea (to be honest, I think it's a bad idea in most cases). Graphical notations are great for providing abstract model views or sketching ideas on the whiteboard, but using them for programming purposes (That's what modelling in the sense of MDSD actually is) is very inconvenient (more or less depending on the tool you use). I think all the UML stuff is a hangover from the old CASE tool days, and of course the OMG needed to put some value into it's MDA "standard".
If you have a real DSL (where the domain is the customer's domain) you should use the syntax your customer prefers of course. Most of the time the DSL is software centric, so you should have a syntax your domain expert (programmer in this case) is used to. This might be UML, but in my case it is not.
To cut a long story short I needed good and simple tooling for textual DSL design.
So I developed a framework called 'xText'. It's based on openArchitectureWare 4.1 (not yet released), EMF and Antlr. With xText one can desribe textual DSLs using an EBNF-like grammar language. The framework generates an EMF-based AST-Metamodel, a corresponding parser and an eclipse text editor plugin from that.
The generated parser instantiates dynamic EMF-models (AST) and the editor provides, syntax highlighting, an outline view and syntax checking as well as semantically checking (based on an additional Check file).
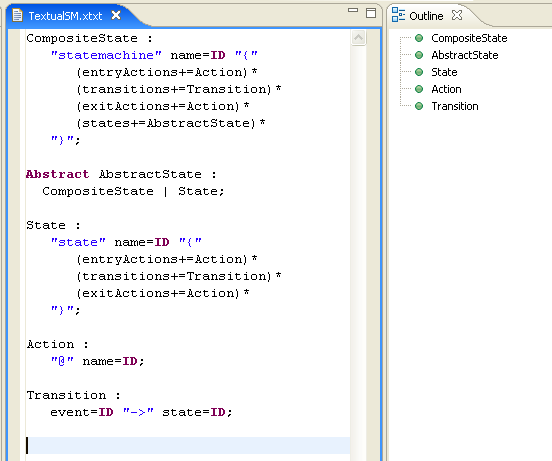
Here is an example of a grammar for a textual language for state machines(shown in the boostrapped grammar editor):
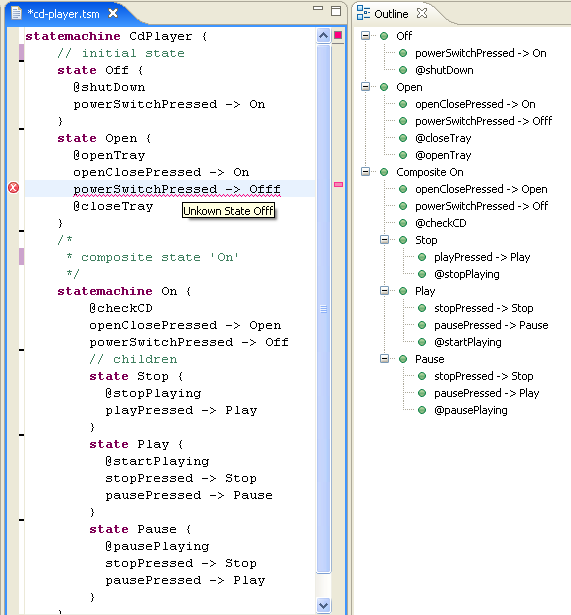
Here is a CD-Player described using the textual DSL (represented in the generated editor):
Grammar
The Grammar language consists of two core abstractions: Rules and Tokens.
Tokens
For now there are the following token types available:
- keyword or symbol (e.g. "state", "{")
- ID (an identifier)
- STRING (a string)
Rules
The main concept are rules. Let's have a look by example:
State :
"state" name=ID "{"
(entryActions+=Action)*
(transitions+=Transition)*
(exitActions+=Action)*
"}";
Each rule has a name (State). This is by convention the name of the corresponding AST type, too.
In our example a state starts with the keyword "state" followed by an identifier (i.e. ID) which is assigned to the property 'name' of the AST type.
Then an opening curly bracket (i.e. "{") is expected.
Next up one or more Actions (described in it's own rule) are assigned to the reference 'entryActions'. The '+=' operator specifies that 'entryActions' is a list, and the Action should be added to it.
Then one or more Transitions are added to the 'transitions' reference, before the following actions are added to the 'exitActions' reference.
The description of a state is terminated using the closing curly bracket ("}").
The AST type 'State' needs to have:
- a property 'name': String
- a reference 'entryActions': List
- a reference 'transitions' : List
- a reference 'exitActions' : List
Note that the AST metamodel can be derived from the grammar.
Abstract rules
Another rule type are abstract rules.
Abstract AbstractState :
State |
CompositeState;
An abstract rule (preceeded by the Abstract keyword) points to an abstract AST type (AbstractState). The body of the rule consists of alternatives (State and CompositeState) to other rules. The AST types of the called rules (State and CompositeState) must be compatible with this rule's abstract AST type (AbstractState).
If the metamodel is automatically generated xText automatically creates a corresponding type hierarchy. Additionally xText 'normalizes' the types (i.e. moves properties contained in all subtypes to the abstract super type).
The derived metamodel of the statemachine example shows how all the general features for State and CompositeState have been moved to there common super type AbstractState:
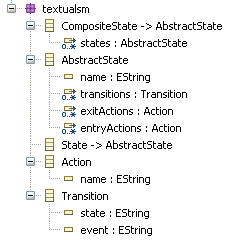
Note that the generation of the AST metamodel is optional! You could design it by hand, if you want to.
String rules
String rules can be used, to describe more complex strings. There is no string rule in our statemachine example so this is how the rule for a Java-like fully qualified name (e.g. my.namespace.Type) looks like:
String fqn :
ID ("." ID)*;
For string rules the tokens are simply concatenated. That's all.
Semantically checking
The editor (and the parser) automatically check whether your description is syntactically correct. If you want to have additional semantically constraints checked (and you should :-)) you just have to write a corresponding Check file.
The screenshot with the CD-Player example shows an error based on this check:

Checks are evaluated by the editor (in the save cycle) and by the generated parser.
What's next
For now the framework is just in CVS (openArchitectureWare on sourceforge). I'm going to get some more experience with it in the next weeks, so I can remove / add / clean up some concepts.
If you have some ideas or thoughts about it, let me know!
Feedback is highly apreciated!